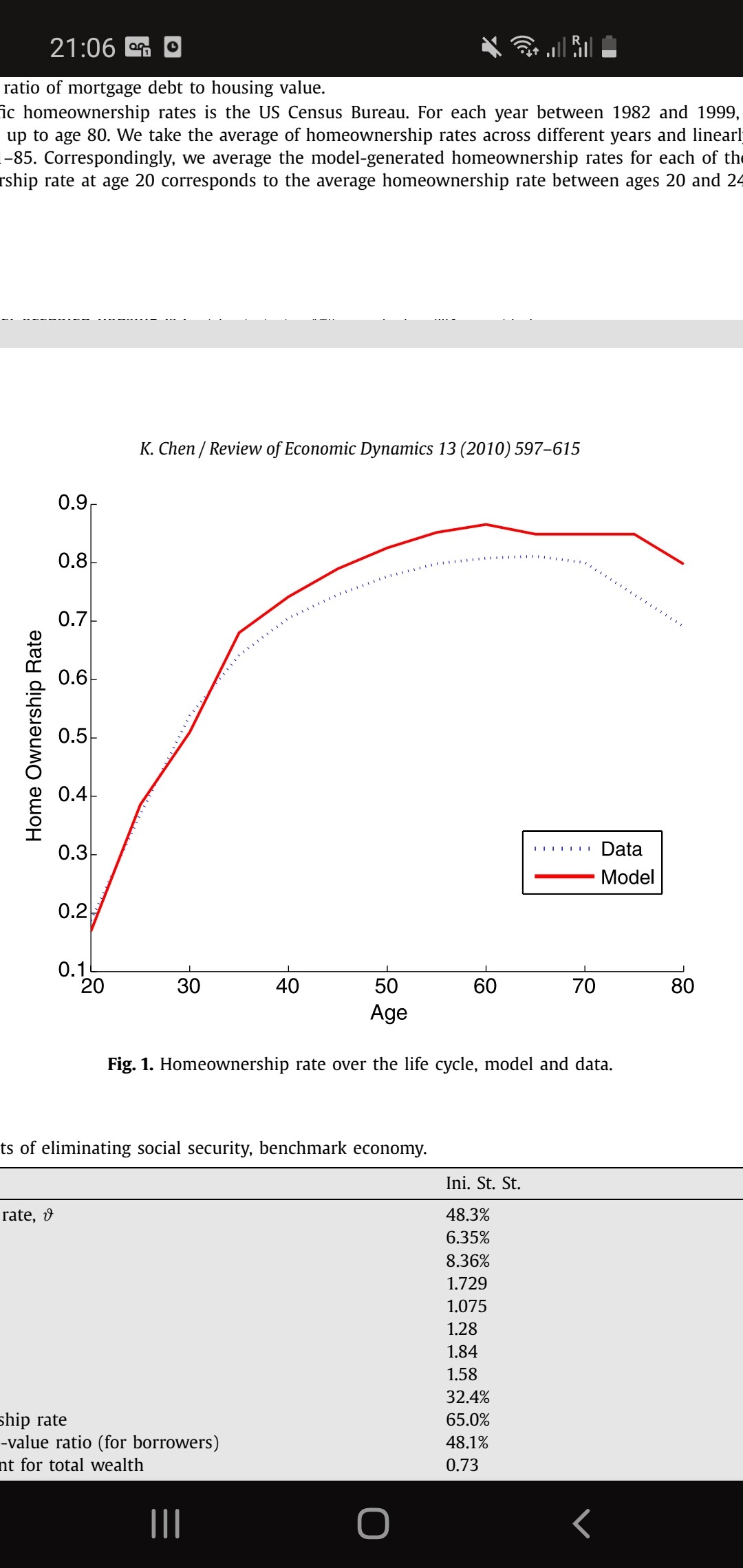
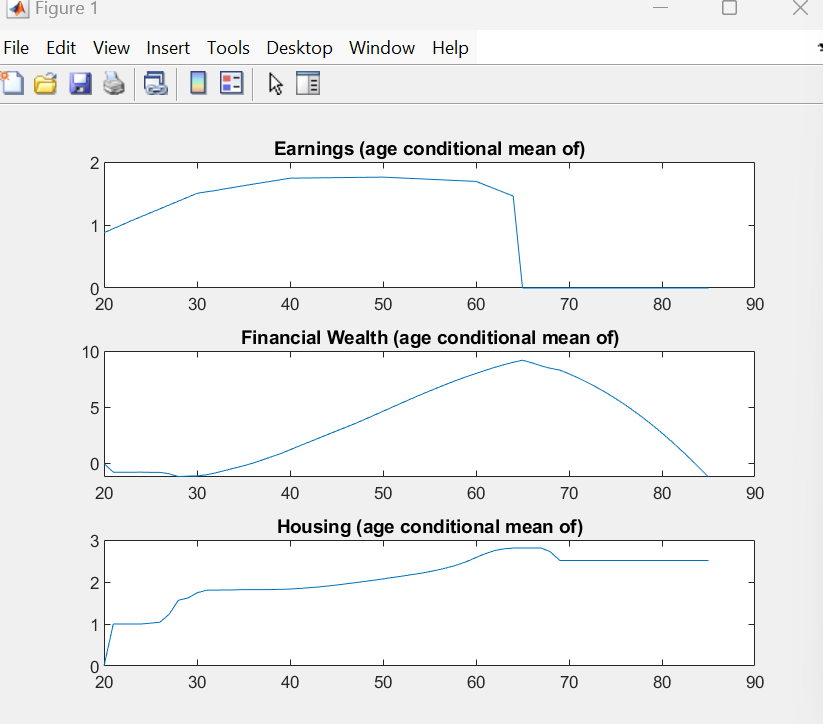
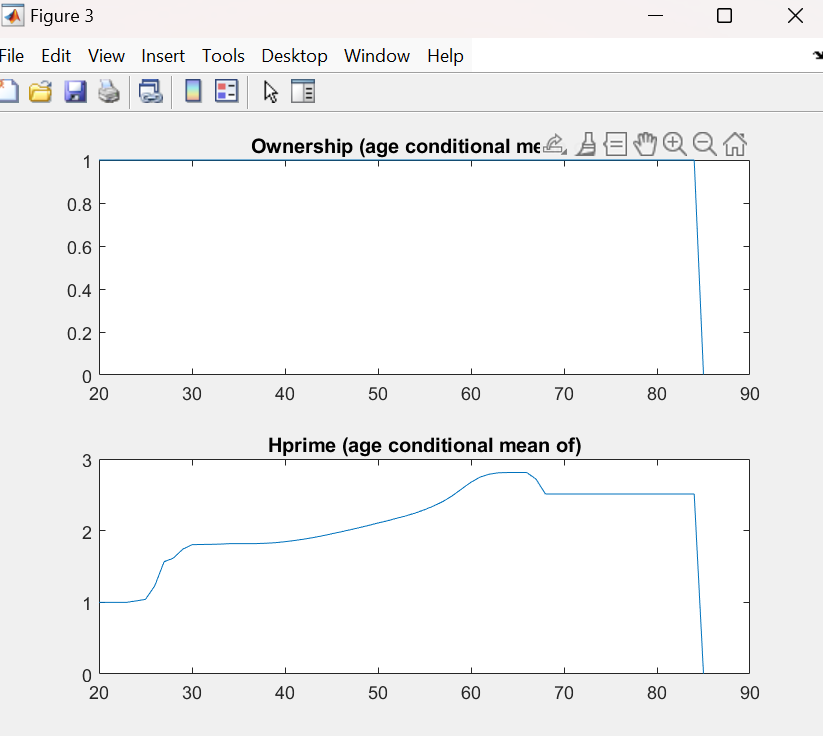
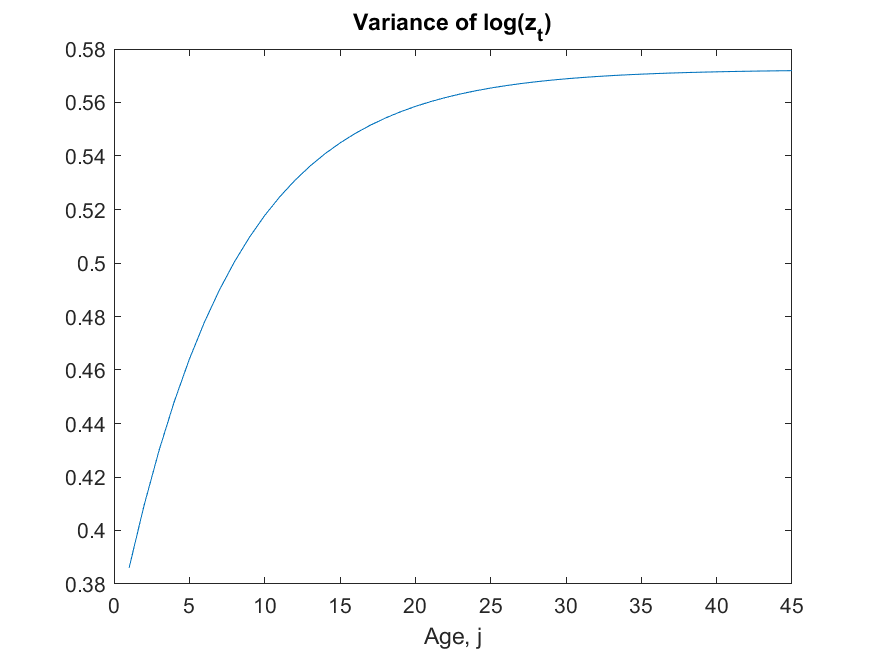Tauchen discretization
I was looking at the Fortran codes and here’s what I understood (admittedly not very well explained in the paper):
sigma_z_epsilon=0.045 is the variance, not the standard deviation, of the innovation to the productivity shock z.- The Tauchen parameter for the spacing of the grid is set equal to sqrt(n/2) where n=num of states. Since n=7, we should set
Tauchen_q=sqrt(7/2);
- After computing the grid for
log(z), Chen normalizes so that z has mean one.
Here is his Fortran code, see subroutine mchain2.f90. Note that in the subroutine he has several ways of discretizing the shocks. He chooses case 6 which is “Huggett 1996”
case(6) ! Hugget (1996)
rho = 0.96
sigma2eps = 0.045 ! Variance of the innovation
sigma2y1 = 0.38 ! Variance of the initial condition eta(1) at age 1
sigmaeps= sqrt(sigma2eps)
! Inputs: rho, sigmaeps, ns
! Outputs: states (grid). stae (invariant distrib), probs (transition matrix)
! Width of Tauchen??
call Tauchen (states, stae, probs, rho, sigmaeps, ns)
Note that the width of Tauchen is defined inside the Tauchen subroutine. I looked in Tauchen.f90 and here is the relevant part:
! define the discrete states of the markiv chain
sigy = sig/sqrt(1.0-rhot**2)
y(n) =sqrt(n+0.0)/sqrt(2.0)*sigy
y(1) = -y(n)
do yc =2, n-1
y(yc)=y(1)+(y(n)-y(1))*(yc-1.0)/(n-1.0)
end do
It is not very explicit, but it seems that tauchen_q = sqrt(n+0.0)/sqrt(2.0) hence sqrt(7/2). Please let me know if I missed something or if you have a different interpretation
Based on this understanding, I would replace a few lines of Robert’s code with the following:
tauchenoptions=struct();
Tauchen_q=sqrt(7/2); % plus/minus two std deviations as the max/min grid points
[z_grid,pi_z]=discretizeAR1_Tauchen(0,Params.rho_z,sqrt(Params.sigma_z_epsilon),n_z,Tauchen_q,tauchenoptions);
z_grid=exp(z_grid); % Ranges from 0.7 to 1.4
% Stationary distribution of pi_z
aux = pi_z^1000;
prob_stat = aux(1,:)';
z_mean = dot(z_grid,prob_stat);
z_grid = z_grid/z_mean;
Note that I take the sqrt of the variance and that I do the normalization
EDIT
I managed to compile and run the Fortran code and I have verified that the z_grid is correct (here “correct” means that it matches what Chen does).