Now for me to talk shit about what all of this means. Half of this post will probably end up coming true, and the other half will not. I am just going to talk about what this means for how to solve Economic models. I won’t try to guess what it means for what we will do with the models, or how it will change the Economics Profession. What follows is me trying to understand how AI coding is going to change Economic modelling, first thoughts not final thoughts.
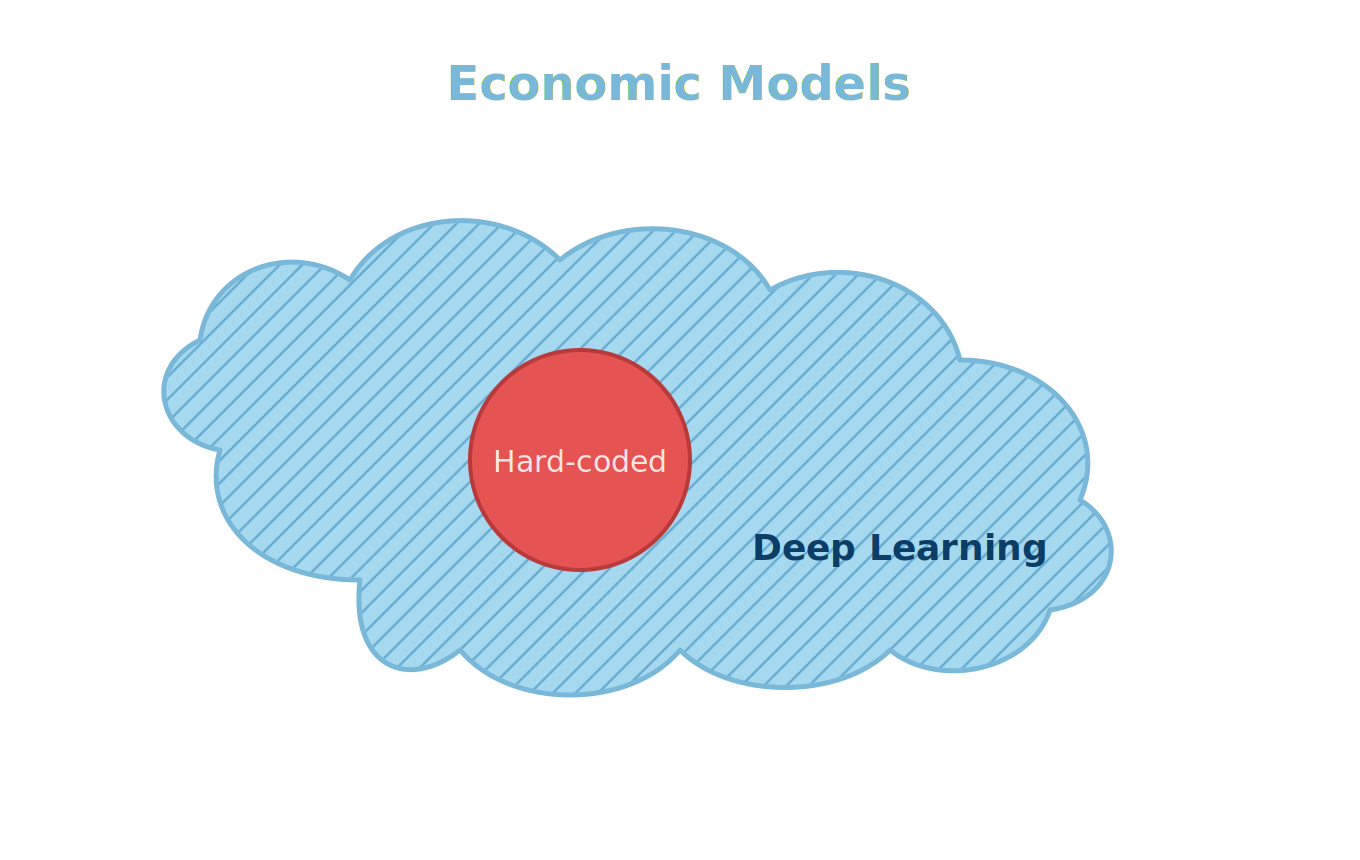
Imagine that “all” Economic models are a cloud
At a high-level there are two approaches to solving each Economic model: we can hardcode the solution, or we can use Deep Learning to solve.
In a head-to-head for any given model, hard-coding will win. It takes advantage of known properties of the model as well as various tricks that are encoded in the hard-code. By contrast, Deep Learning (DL) will have to expend a lot of compute trying to understand the shape of the problem on the way to solving. Both can solve the model, but the DL is just much more compute intense, and so slower.
But much as compute intensity and thus runtimes are the Achilles heel of DL, the Achilles heel of hard-coding is that someone has to hard-code it! This means one code for every model. There are tens or even hundreds of thousands of models. Dynare probably solves a few thousand, VFI Toolkit solves a few hundred by my rough count. And so most models are just not going to be hard-coded, and DL will be used for, say, 90% of models. Our cloud of models thus looks like
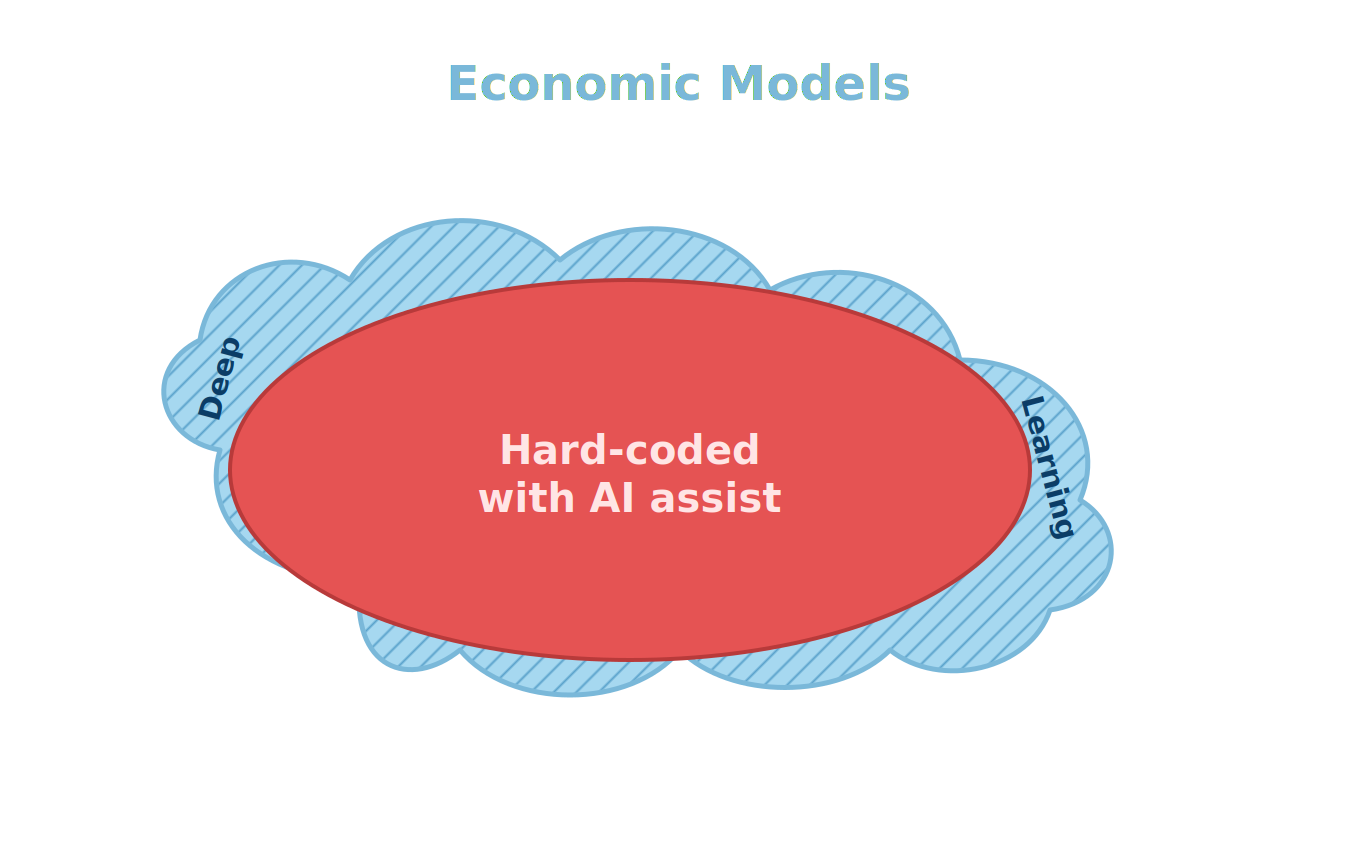
If you asked me between one and five years ago, this was the end of the story. VFI Toolkit would hard-code a core of models, maybe even a thousand of them! But then AI Coding arrived. Last week I AI coded a few dozen models in an afternoon, which in the past would have taken a week or three, and it wasn’t even the main thing I was doing that afternoon. Suddenly with AI Coding it is easy for VFI Toolkit to solve a few thousand models, and getting there will only take a year. Hard-coding ten thousand models seems do-able given three or four years. And just like that the red circle has been renamed ‘Hard-coded with AI assist’ and now it has grown to fill most of the cloud
AI Coding has made it not just possible but likely that we can simply hard-code just about every Economic model we want to solve. We can even code each one a few times to find the best algorithms and rather than users having to understand all the algorithms the hard-coding simply embeds and records all that expert knowledge of how to solve each model. The Achilles heel of having to code each one has been ameliorated by AI coding, dragging us back to the Styx for another dunking.
Where does this leave Deep Learning, seemingly relegated to the dark fringes of the cloud? First, Deep Learning will still play an important role in solving some of the most advanced models, where people have compute to throw at them and little idea how else to solve them. Second, it suggests an important new role for Deep Learning. It is understood that one of the strengths of Deep Learning for solving models is its ability to find dimensionality-reductions. Deep Learning can be used to solve a model type once, find and understand the best tricks for that model —say a change of basis, like state-space versus sequence-space, or a functional form, like Chebyshev polynomials or Akima splines— and then these can be hard-coded on a model-by-model basis. Hopefully we see some work take up the challenge of using Deep Learning to fulfil this new role. Third, I may be wrong and instead Deep Learning changes the kinds of models Economists solve, more Q-Learning AlphaGo models that are amazing at winning Go competitions while being largely a black-box on tactics. I put low odds on this, Economics is much more interested in understanding and in (non-local) counterfactuals than other areas, as evidenced by the stranglehold of the Lucas Critique in Macroeconomics.
AI Coding also increases the value of improved algorithms that we can hard-code, because it slashes the cost of adopting them. We can even set them as options that the user can choose from to solve the model. VFI Toolkit already has ‘divide-and-conquer’, ‘grid interpolation layer’ and ‘fastOLG’, and it benefits immensely from having adopted the Tan improvement. The advent of new algorithms, like Endogenous Grid Method, BKM, and Matched-Expectation Path means rewriting all our hard-coded models, but with AI Coding this is no longer a daunting prospect, it is something we can reasonably do.
That’s my guess at how the cloud of Economic models develops. For sure I am half-wrong — as Yogi Berra (probably didn’t) say, “it’s tough to make predictions, especially about the future.” And while I’ve read a lot of papers on Deep Learning I’ve never done more than dabble with it. But the through-line I’m most confident about is that AI Coding pushes the binding constraint away from writing solvers and onto everything else — choosing models, interpreting them, knowing which question to ask. Should make for some fun Economics!
—--------------
Give me some examples of this head-to-head between hard-coding and Deep Learning you say? Let’s consider global non-linear solutions of models with incomplete markets and aggregate shocks. DeepHam takes 30-40 minutes to solve the Krusell-Smith 1998 model. Abbott and Nam fuse hard-coded finite differences onto DL and get 10 minutes. Hard-coding the Matched-Expectations Path and suddenly it takes just one minute (beta functionality in VFI Toolkit, will be public towards the end of this year). All three of these runtimes use very similar GPU hardware. More generally, just look at the amount of compute being used in the average DL paper, you can easily see how demanding they are.
What might 'using Deep Learning to find dimensionality-reductions look like? Not quite sure, but Section 3.2 of Gordon-Wilson (2025WP) discusses the ‘effective dimensionality’ of Deep Learning solutions, and it makes sense we could develop further tools for seeing what the dimensions are. Once we know the dimensions a solution should occupy, it makes sense you can hard-code solution methods that directly exploit these known dimensions.
A quick clarification on what I mean by hard-coding a model. I do not mean writing code for a specific example/application like HV2000. I mean writing code that solves a specific model-framework with a specific algorithm. For example ValueFnIter_FHorz_QuasiHyperbolicN_DC1_GI1_nod_raw() from deep inside VFI Toolkit. This code solves a finite-horizon value fn problem (ValueFnIter_FHorz) using divide-and-conquer and grid interpolation layer on one endogenous state (_DC1_GI1) for a model with no decision variables (_nod) and a markov shock (implicit) for Naive Quasi-Hyperbolic discounting (note the N). If you look in the same folder, there are sixteen codes solving with/without d/z/e and Naive/Sophisticated Quasi-Hyperbolic discounting. Neighbouring folders do _DC1 and _GI1, separately, and one folder up and the codes for pure discretization. When I say I wrote a few dozen models in an afternoon, these are what I am referring to, codes that solve model-frameworks. This is why I think AI Coding massively increases the returns to building toolkits, because we can now code thousands of frameworks.
I should probably clarify that I am in favor of the stranglehold that the Lucas Critique has on Macroeconomics