Just uploaded codes implementing Attanasio, Low & Sanchez-Marcos (2008) - Explaining Changes in Female Labor Supply in a Life-Cycle Model
Codes and pdf of model: https://github.com/robertdkirkby/LifeCycleOLGReadingList/tree/main/AttanasioLowSanchezMarcos2008
Comments:
i) paper is a bit messy on equations and parameters, so not 100% sure parameters are all correct in my codes
ii) model has bivariate joint-unit root, you should renormalize model to remove this from state space, but I just discretize it and solve. Means code is solving a ‘harder’ problem, but also makes it easy to change to any other process on earnings shocks.
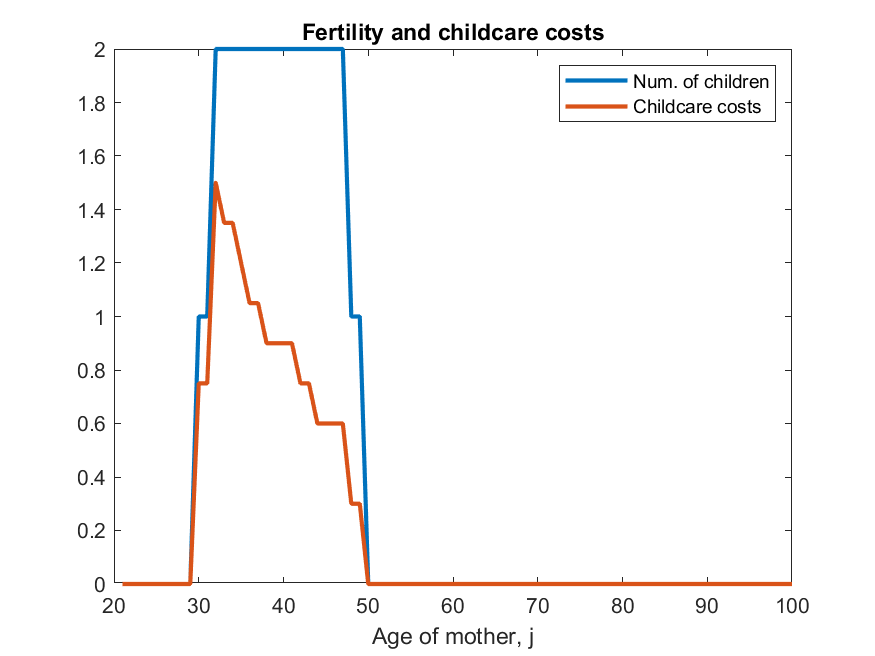
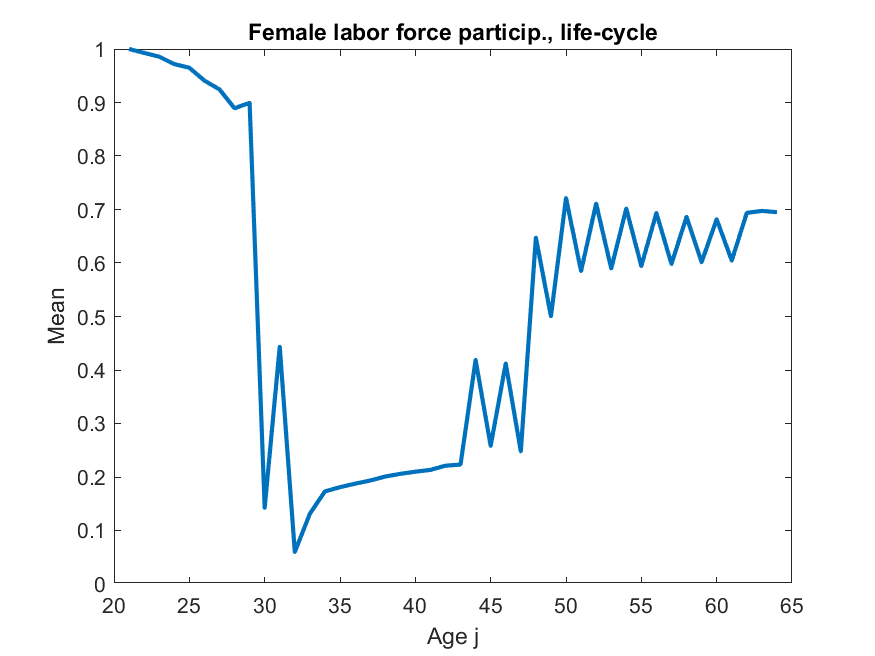
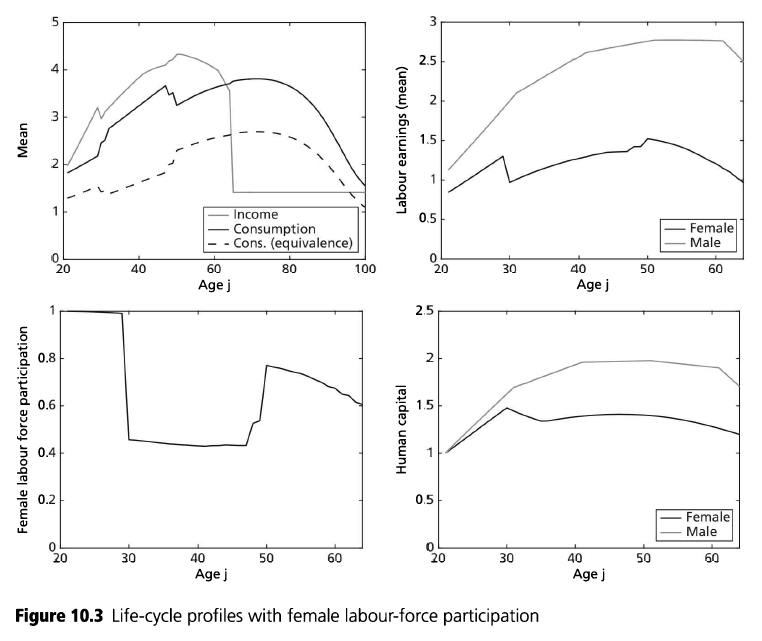
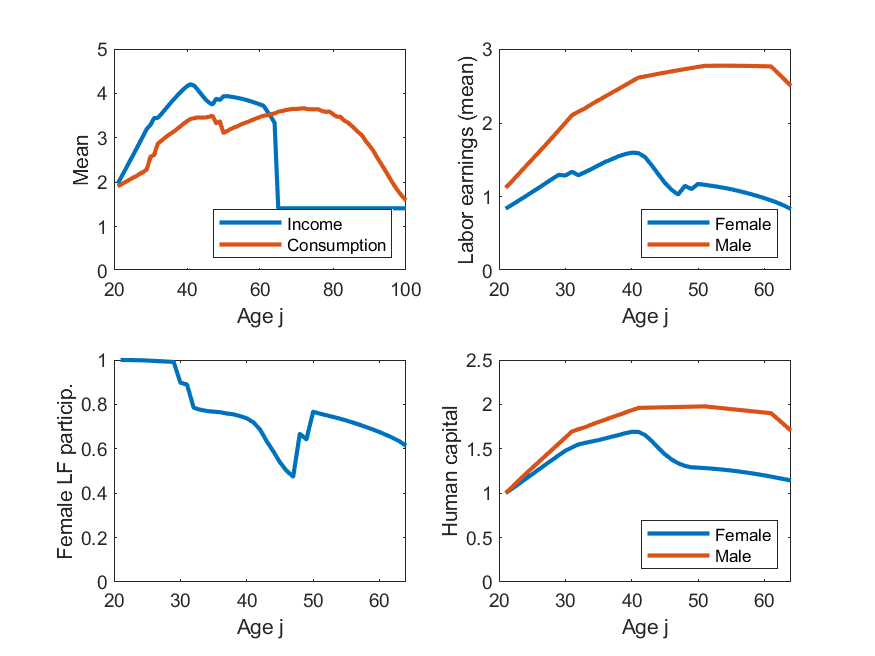
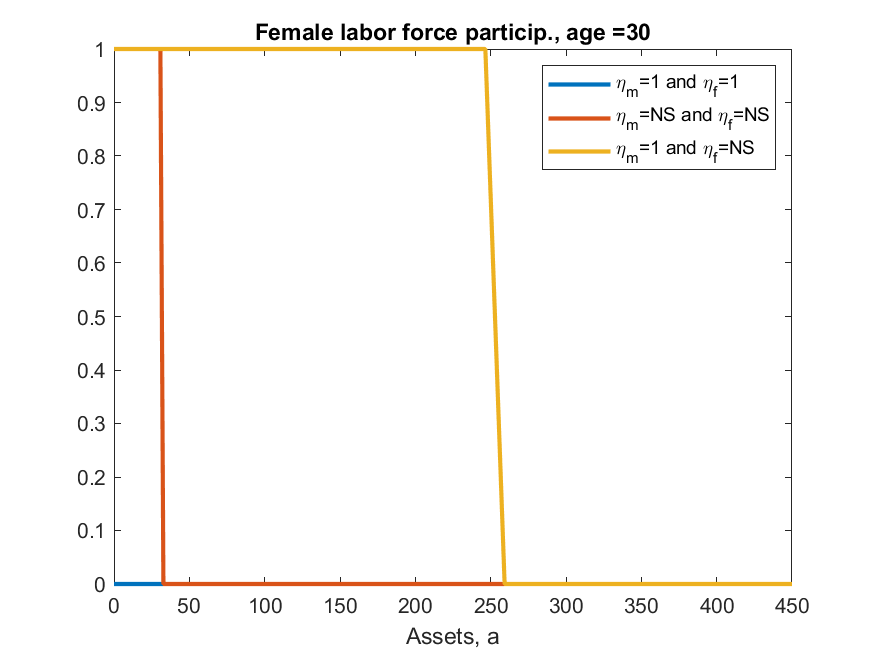
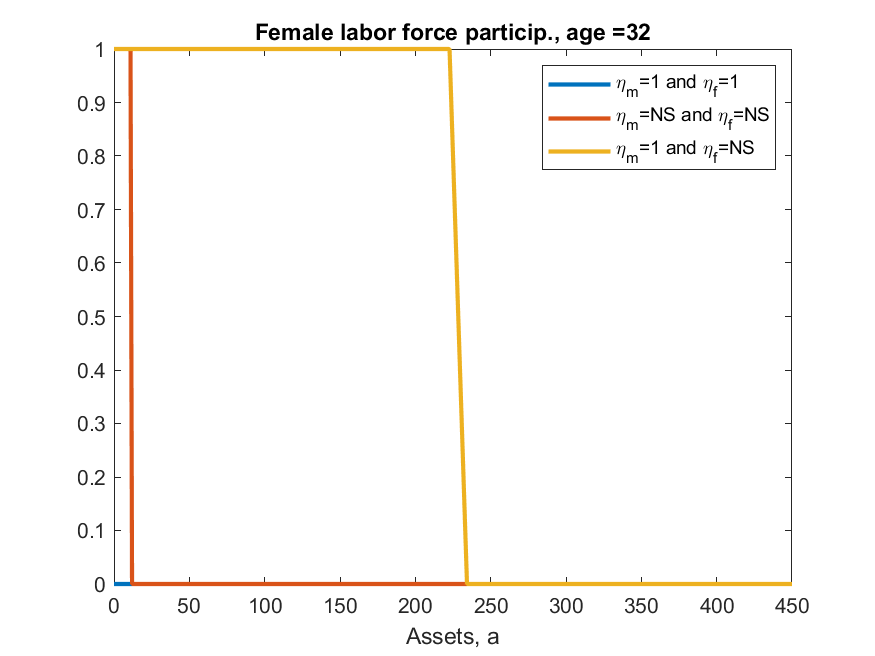
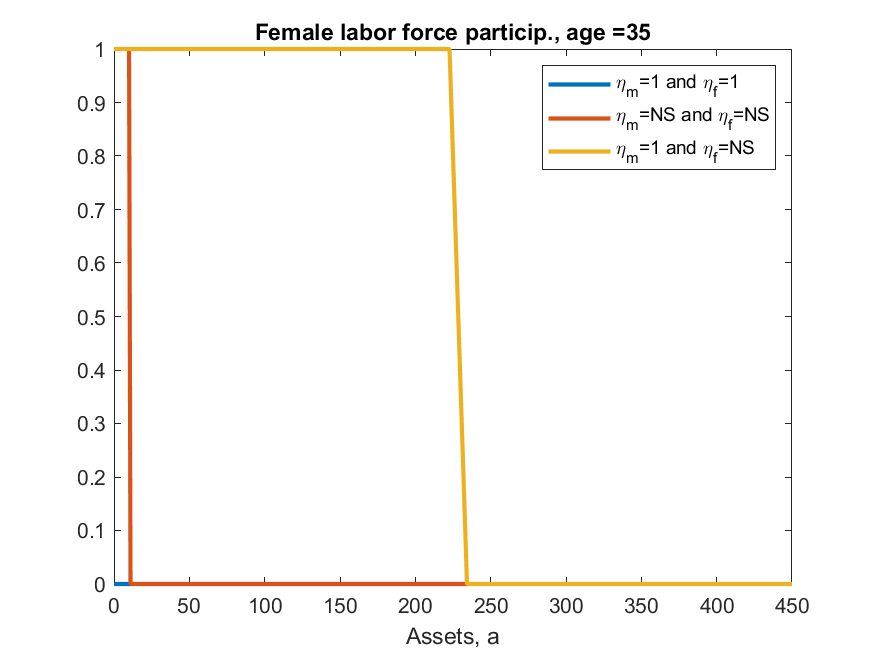
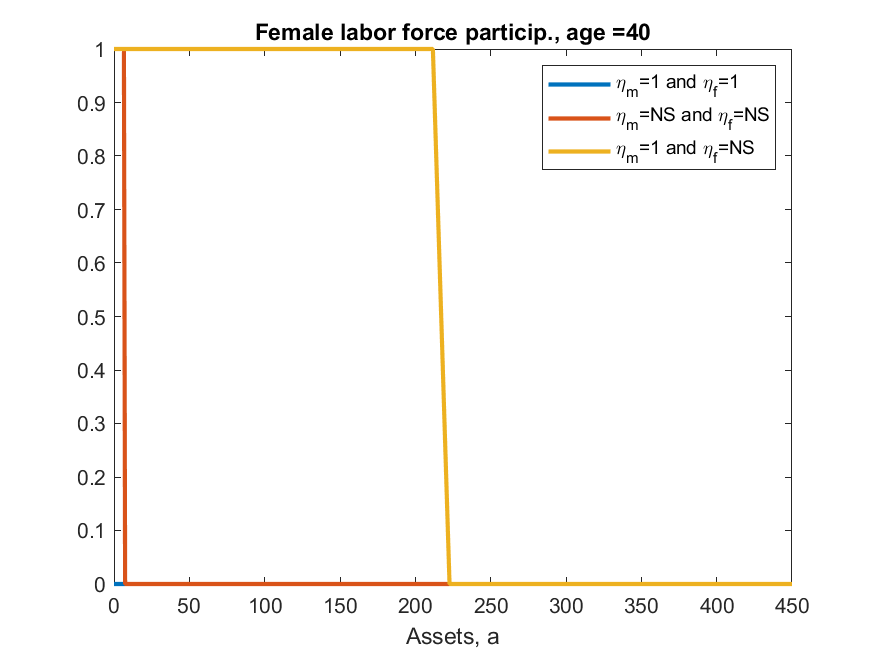
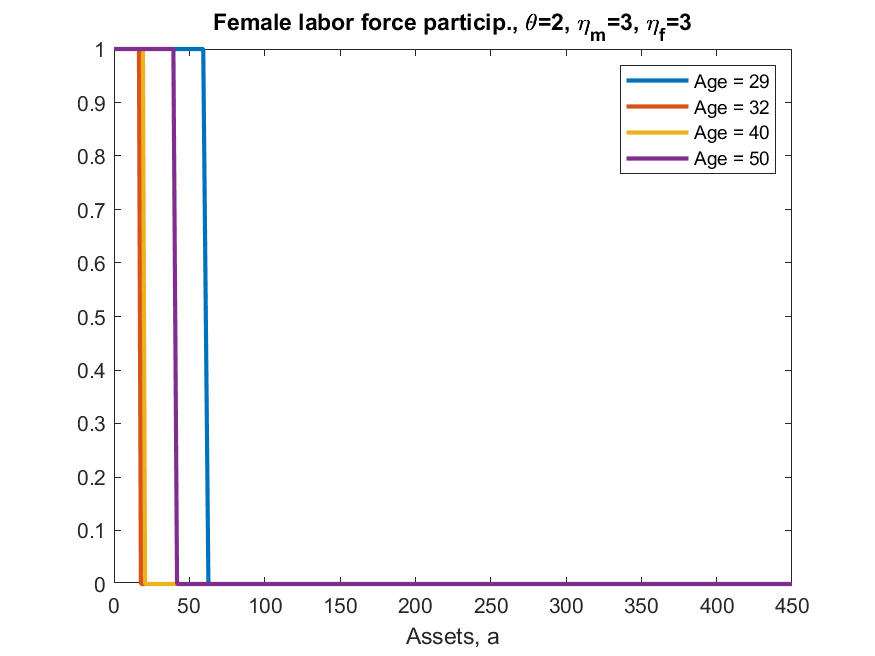
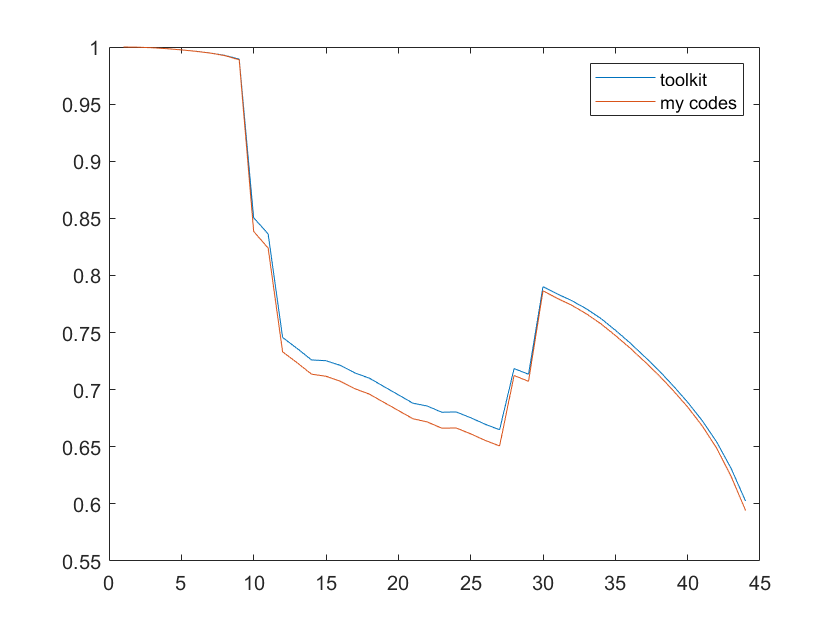
iii) results differ from ALSM2008, main direction is always the same but, e.g., ALSM2008 report that 47% of women with children under 3 work, while here codes say 2%. [look at Figure 10 in paper and code and you can see the shape is identical, just the magnitude is very different]
iv) decent odds that (iii) relates to (i) [of course maybe there is just a mistake in my code, but I can’t see it, or maybe there is error in ALSM2008 original code]
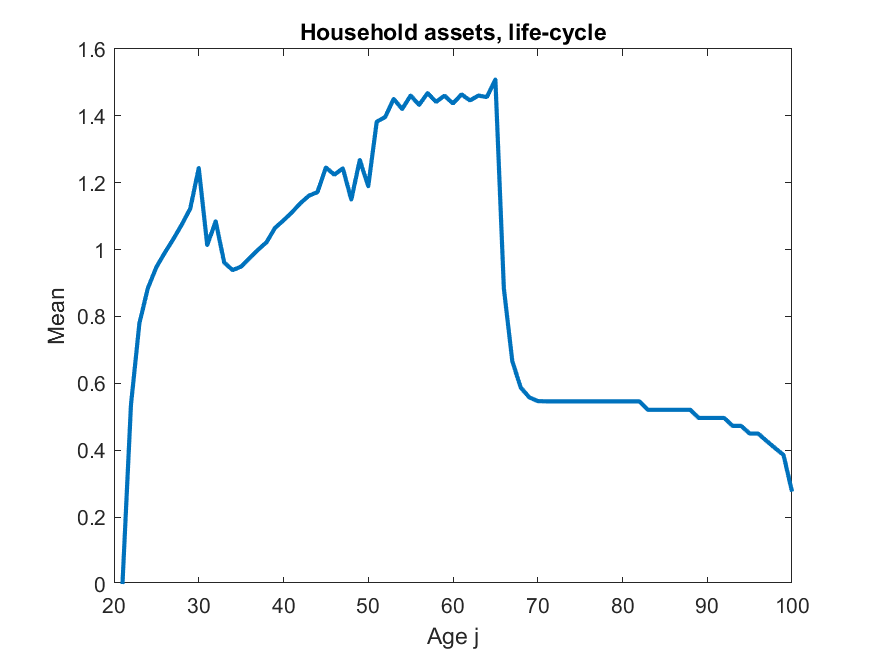
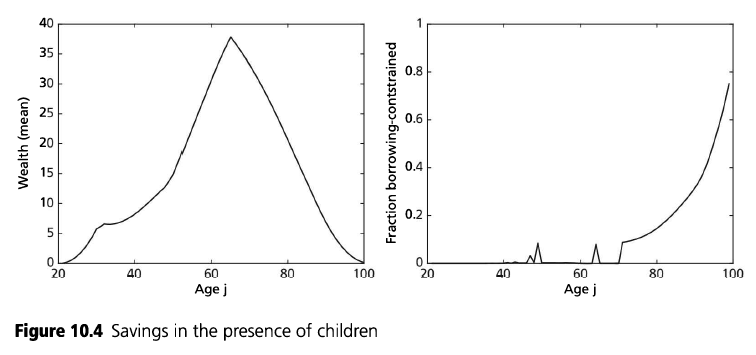
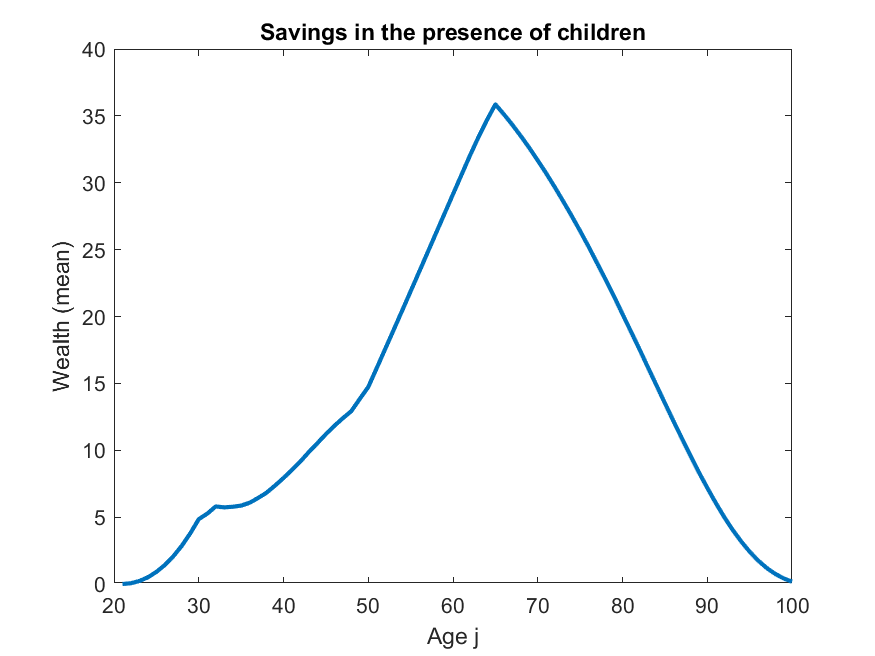
v) behaviour of assets in model is very unrealistic, this may also be related to (i), ALSM2008 do not report any results relating to assets, so not sure if theirs looked more reasonable. That said, this is a model without retirement (nor a warm glow target level of assets to substitute for it) so the asset profile may well just be supposed to look this way.
This example shows two things in toolkit not yet seen elsewhere. One is discretizing a life-cycle VAR(1), second is ‘experienceasset’ which is used to model the ‘history of female labor force participation’ (h_f in model). ‘experienceasset’ can be used for many kinds of human capital models and will get properly documented sometime late next year.
[Requires a fairly powerful gpu to run as is, but if you just want to play with it then make the grids smaller and will be fine on standard desktop gpu. Even with grids half the size I got same results.]
[The original fortran codes and data work are available on Low’s website]